반응형
1. 논문 개요
"Accurate Multivariate Stock Movement Prediction via Data-Axis Transformer with Multi-Level Contexts" (DTML)는 주식 가격의 상승/하락을 예측하는 모델로, Transformer를 활용해 주식 간 동적/비대칭 상관관계를 학습합니다. 기존 모델이 개별 주식만 보거나 고정된 섹터 정보를 썼다면, DTML은 end-to-end 방식으로 상관관계를 자동 추출합니다.
- 목표: 다변량 주식 데이터를 활용해 정확한 움직임 예측.
- 데이터셋: US(ACL18, KDD17, NDX100), China(CSI300), Japan(NI225), UK(FTSE100).
- 성과: SOTA 달성(최대 ACC 57.44%, MCC 19.10%), 투자 시뮬레이션에서 연수익률 44.4%.
2. DTML의 3단계 구조
DTML은 세 가지 모듈로 주식 움직임을 예측합니다 (논문 Figure 2 참고).
2.1 Attentive Context Generation
- 입력: 주식별 다변량 시계열 (예: z_open = open_t / close_t - 1, Table 3).
- 방법: Attention LSTM으로 시간적 패턴 요약.
- Feature Transformation: tanh(Wz + b)로 변환.
- LSTM + Attention: a_i = exp(h_i^T h_T) / sum(...), h^c = Σ a_i h_i.
- Normalization: LayerNorm으로 안정화.
- 의미: 각 주식의 과거 데이터를 압축해 중요한 날만 강조.
2.2 Multi-Level Context Aggregation
- 입력: 개별 주식 컨텍스트(h_u^c) + 시장 지수 컨텍스트(h^i).
- 방법: h_u^m = h_u^c + β h^i (β는 하이퍼파라미터, 예: 0.1).
- 의미: 글로벌 시장 트렌드(예: SNP500)를 반영해 상관관계 강화.
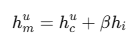
2.3 Data-Axis Self-Attention
- 입력: Multi-Level 컨텍스트 행렬(H ∈ ℝ^{d × h}).
- 방법: Transformer Encoder로 주식 간 상관관계 학습.
- Multi-Head Attention: Q = HW_q, K = HW_k, V = HW_v, S = softmax(QK^T / √h).
- Nonlinear Transformation: H_p = tanh(H + H̃ + MLP(H + H̃)).
- 출력: ŷ = σ(H_p W_p + b_p).
- 의미: 주식 간 비대칭 영향(예: Amazon → Google ≠ Google → Amazon)을 계산.
3. 구현 핵심
논문을 PyTorch로 구현하며 한국 주식 데이터를 적용했습니다.
3.1 데이터 전처리
- 소스: SQLite (charts_koreastock, charts_koreaindex).
- Feature: 논문 Table 3 기반 (z_open, z_high, z_low, z_close, z_d5~30).
- 구성: [num_samples, d, seq_len, feature_dim] (예: seq_len=15, d=종목 수).
- Split: Train(70%), Val(10%), Test(20%).
3.2 모델 코드
class DTML(nn.Module):
def __init__(self, stock_input_dim, index_input_dim, hidden_dim, num_heads=8, beta=0.1):
super().__init__()
self.stock_attn_lstm = AttentionLSTM(stock_input_dim, hidden_dim) # 주식별 컨텍스트
self.index_attn_lstm = AttentionLSTM(index_input_dim, hidden_dim) # 시장 컨텍스트
self.data_axis_attn = DataAxisSelfAttention(hidden_dim, num_heads) # 주식 간 상관관계
self.prediction = nn.Linear(hidden_dim, 1) # 예측
def forward(self, stock_x, index_x):
h_c = self.stock_attn_lstm(stock_x.view(-1, stock_x.size(2), -1)).view(stock_x.size(0), stock_x.size(1), -1)
h_i = self.index_attn_lstm(index_x)
h_m = h_c + self.beta * h_i.unsqueeze(1) # Multi-Level 결합
H_out, attn_map = self.data_axis_attn(h_m) # Data-Axis Attention
return torch.sigmoid(self.prediction(H_out).squeeze(-1)), attn_map3.3 학습 설정
- 하이퍼파라미터: hidden_dim=64, num_heads=4, beta=0.1, lr=0.001, reg_lambda=1.0.
- 탐색: seq_len = [10, 15] (논문 Section 4.1).
- Early Stopping: Val Loss 기준, patience=10.
- Loss: BCE + Selective Regularization (λ * (||W_p||_F^2 + ||b_p||_2^2)).
4. 실험 결과
4.1 학습 결과
- seq_len=15 / Model Acc: 0.5742 (논문과 유사한 결과)
4.2 Attention Map
- 논문 Figure 3처럼 주식 간 영향력 시각화 (sns.heatmap(attn_map)).
- 관찰: 실질적으로 큰 의미가 없어 보임
4.3 논문과의 차이
- 데이터: 한국 주식만 사용 (논문은 6개국).
5. 논문에서 배운 3가지
- Transformer의 유연성: Data-Axis로 주식 간 관계를 효과적으로 학습.
- Multi-Level의 힘: 시장 지수를 추가하면 예측 안정성 ↑.
- Attention의 직관: S 행렬로 주식 네트워크를 해석 가능.
6. 논문 한계
- 한계: 생존 편향, 슬리피지 고려 안함
7. 참고
- 논문 DOI: 10.1145/3447548.3467297
반응형



