Transformer를 코드로 이해해보기 위해 작성한 포스팅이다.
파이토치에 이미 nn.Transformer로 구현되어있지만
사용하지 않고 직접 Pytorch Layer들로 구현하고자 한다.
학습 데이터
한국어 챗봇 훈련용 대화 데이터셋으로
자주 사용되는 ChatbotData.csv를
학습용 데이터로 사용하고자 한다.
import urllib.request
import pandas as pd
urllib.request.urlretrieve("https://raw.githubusercontent.com/songys/Chatbot_data/master/ChatbotData.csv", filename="ChatBotData.csv")
data_df = pd.read_csv('ChatBotData.csv')
data_df.head()
| Q | A | label |
| 12시 땡! | 하루가 또 가네요. | 0 |
| 1지망 학교 떨어졌어 | 위로해 드립니다. | 0 |
| 3박4일 놀러가고 싶다 | 여행은 언제나 좋죠. | 0 |
| 3박4일 정도 놀러가고 싶다 | 여행은 언제나 좋죠. | 0 |
| PPL 심하네 | 눈살이 찌푸려지죠. | 0 |
EDA
먼저, 간단하게 데이터셋을 살펴보고자
간단한 EDA 과정을 진행하고자 한다.
# 데이터 정보 확인
print("데이터 구조 확인:")
print(data_df.info())
# 상위 5개 데이터 확인
print("\n데이터 상위 5개:")
print(data_df.head())
# 결측치 확인
print("\n결측치 확인:")
print(data_df.isnull().sum())
# 중복값 확인
print("\n중복값 확인:")
print(data_df.duplicated().sum())
# label 컬럼 drop시 중복 row 존재
# 데이터의 기본 통계값 확인
print("\n기본 통계값:")
print(data_df.describe())
전처리 및 Vocabulary 구축
데이터셋 전처리 후, Vocabulary와 tokenizer를 만들어보겠다.
import math
import random
import re
import numpy as np
import pandas as pd
from urllib.request import urlretrieve
from collections import Counter
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.utils.data import Dataset, DataLoader
if set(['Q', 'A']).issubset(data_df.columns):
questions = data_df['Q'].astype(str).tolist()
answers = data_df['A'].astype(str).tolist()
else:
raise ValueError("CSV 컬럼명이 예상과 다릅니다. 컬럼명을 확인하세요.")Tokenize
# 간단한 토크나이저 (공백 기준)
def tokenize(text):
text = text.lower().strip()
# 구두점 제거 (기본적인 처리)
text = re.sub(r"([?.!,])", r" \1 ", text)
text = re.sub(r'\s{2,}', ' ', text)
return text.split()
토크나이저는 간단하게 공백 기준으로 나누었다.
Vocabulary
# 특수 토큰
PAD_TOKEN = "<pad>"
SOS_TOKEN = "<sos>"
EOS_TOKEN = "<eos>"
UNK_TOKEN = "<unk>"
class Vocab:
def __init__(self, min_freq=1):
self.min_freq = min_freq
self.word2idx = {}
self.idx2word = {}
self.freqs = Counter()
# 먼저 특수 토큰들을 추가
for token in [PAD_TOKEN, SOS_TOKEN, EOS_TOKEN, UNK_TOKEN]:
self.add_word(token)
def add_word(self, word):
if word not in self.word2idx:
idx = len(self.word2idx)
self.word2idx[word] = idx
self.idx2word[idx] = word
def build_vocab(self, sentences):
for sentence in sentences:
tokens = tokenize(sentence)
self.freqs.update(tokens)
for word, freq in self.freqs.items():
if freq >= self.min_freq and word not in self.word2idx:
self.add_word(word)
def numericalize(self, text):
tokens = tokenize(text)
return [self.word2idx.get(token, self.word2idx[UNK_TOKEN]) for token in tokens]
def __len__(self):
return len(self.word2idx)
vocab = Vocab(min_freq=1)
vocab.build_vocab(questions + answers)
print("Vocab size:", len(vocab))huggingface에서 제공하는 tokenizer의 기능과
유사하게 tokenize 함수와 Vocab Class를 만들었다.
Vocab Class를 통해
idx ↔ word 를 변환하고 단어장을 관리할 것이다.
- add_word : 단어장 추가
- build_vocab : 단어장 생성
- numericalize : 단어 → idx로 치환
Dataset, Dataloader
class ChatDataset(Dataset):
def __init__(self, questions, answers, vocab, max_len=30):
self.questions = questions
self.answers = answers
self.vocab = vocab
self.max_len = max_len # 최대 토큰 길이
def __len__(self):
return len(self.questions)
def __getitem__(self, idx):
# 질문: encoder 입력
src_seq = self.vocab.numericalize(self.questions[idx])
# 답변: decoder 입력 (teacher forcing을 위해 <sos>와 <eos>를 추가)
tgt_seq = [vocab.word2idx[SOS_TOKEN]] + self.vocab.numericalize(self.answers[idx]) + [vocab.word2idx[EOS_TOKEN]]
# 자르기 (max_len보다 길면 자르고, 짧으면 나중에 padding)
src_seq = src_seq[:self.max_len]
tgt_seq = tgt_seq[:self.max_len]
return torch.tensor(src_seq), torch.tensor(tgt_seq)
# train/val/test 분리
data_size = len(questions)
indices = list(range(data_size))
random.shuffle(indices)
train_end = int(0.8 * data_size)
val_end = int(0.9 * data_size)
train_indices = indices[:train_end]
val_indices = indices[train_end:val_end]
test_indices = indices[val_end:]
def subset(data_list, indices):
return [data_list[i] for i in indices]
train_dataset = ChatDataset(subset(questions, train_indices), subset(answers, train_indices), vocab)
val_dataset = ChatDataset(subset(questions, val_indices), subset(answers, val_indices), vocab)
test_dataset = ChatDataset(subset(questions, test_indices), subset(answers, test_indices), vocab)다음으로 학습 데이터를 모델에 제공하기 위해
Dataset과 Dataloader를 만드는 단계이다.
여기서의 특이점은 tgt_seq(답변)은
학습시 teacher forcing을 위해 <sos>와 <eos> 토큰을 앞뒤에 추가한다.
def collate_fn(batch):
src_seqs, tgt_seqs = zip(*batch)
# 길이에 따라 pad
src_lens = [len(s) for s in src_seqs]
tgt_lens = [len(t) for t in tgt_seqs]
max_src = max(src_lens)
max_tgt = max(tgt_lens)
padded_src = torch.full((len(batch), max_src), vocab.word2idx[PAD_TOKEN], dtype=torch.long)
padded_tgt = torch.full((len(batch), max_tgt), vocab.word2idx[PAD_TOKEN], dtype=torch.long)
for i, (src, tgt) in enumerate(zip(src_seqs, tgt_seqs)):
padded_src[i, :len(src)] = src
padded_tgt[i, :len(tgt)] = tgt
return padded_src, padded_tgt
batch_size = 64
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True, collate_fn=collate_fn)
val_loader = DataLoader(val_dataset, batch_size=batch_size, shuffle=False, collate_fn=collate_fn)
test_loader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False, collate_fn=collate_fn)collate_fn을 통해 배치(batch) 데이터를 커스터마이징 한다.
- 배치 내의 데이터 길이가 다를 때 패딩 처리
- 배치를 특정 형식(예: 텐서)으로 변환할 때
- 추가적인 데이터 전처리가 필요할 때
Transformer 구조
- Positional Encoding
- Self-Attention (Scaled Dot-Product Attention)
- Multi-Head Attention
- Feed Forward Network
- Residual Connection + Layer Normalization
먼저, 간단하게 Pytorch로 Transformer 모델을 구현해보고자한다.
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")Positional Encoding
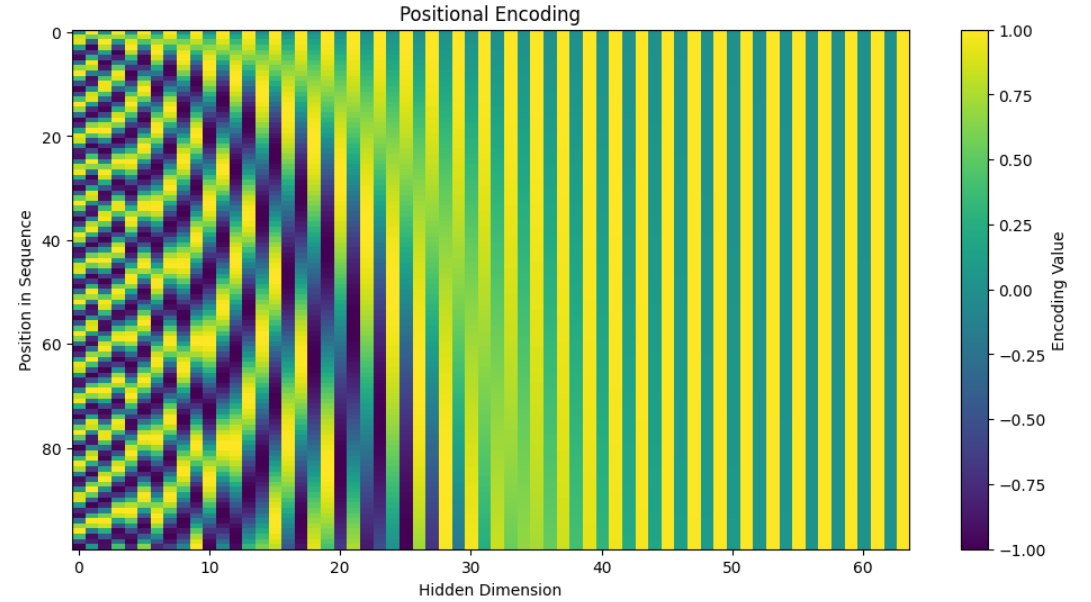
포지셔널 인코딩은 시퀀스의 순서를 학습하기 위해 입력에 위치 정보를 추가하는 방법으로
일반적으로 사인(sin)과 코사인(cos) 함수를 사용해 위치 정보를 임베딩에 반영한다.

# 포지셔널 인코딩
class PositionalEncoding(nn.Module):
def __init__(self, d_model, max_len=5000):
super(PositionalEncoding, self).__init__()
pe = torch.zeros(max_len, d_model) # (max_len, d_model)
position = torch.arange(0, max_len, dtype=torch.float).unsqueeze(1) # (max_len, 1)
div_term = torch.exp(torch.arange(0, d_model, 2).float() * (-math.log(10000.0) / d_model))
pe[:, 0::2] = torch.sin(position * div_term) # 짝수 인덱스
pe[:, 1::2] = torch.cos(position * div_term) # 홀수 인덱스
pe = pe.unsqueeze(0) # (1, max_len, d_model)
self.register_buffer('pe', pe)
def forward(self, x):
# x: (batch_size, seq_len, d_model)
seq_len = x.size(1)
x = x + self.pe[:, :seq_len, :]
return x포지셔널 인코딩 layer는 학습 대상이 아닌 텐서이기에
self.register_buffer('pe', pe)를 사용해서
역전파에 의해 값이 수정되지 않게 한다.
Scaled Dot-Product Attention
스케일드 닷 프로덕트 어텐션은 쿼리(Query)와 키(Key)의 내적(dot product)을 통해 어텐션 스코어를 계산하고,
이를 소프트맥스로 정규화해 가중치를 얻은 뒤 값(Value)과 곱해 출력한다.
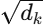
어텐션 스코어를 계산할 때 값이 너무 커지는 것을 방지하기 위해 사용하는 스케일링 요소
- QK^T의 값이 d_k (임베딩 차원)가 커질수록 값이 너무 커질 수 있음
- 값이 커지면 소프트맥스(softmax)의 출력이 매우 작아지거나, 기울기(gradient)가 사라지는
기울기 소실(vanishing gradient) 문제가 발생할 수 있음. - 따라서 d_k의 제곱근으로 나눠주면 값이 적절하게 스케일링되어 학습이 안정화됨

def scaled_dot_product_attention(query, key, value, mask=None, dropout=None):
d_k = query.size(-1)
scores = torch.matmul(query, key.transpose(-2, -1)) / math.sqrt(d_k) # (batch, head, seq_q, seq_k)
if mask is not None:
scores = scores.masked_fill(mask == 0, -1e9)
attn = F.softmax(scores, dim=-1)
if dropout is not None:
attn = dropout(attn)
output = torch.matmul(attn, value)
return output, attn중간에 mask는 디코더에서 미래 시점의 정보를 차단하거나,
패딩된 부분을 무시할 때 사용 (Padding Mask, Look-ahead Mask)
Multi-Head Attention
멀티 헤드 어텐션(Multi-Head Attention)은 쿼리(Query), 키(Key), 값(Value)를
여러 개의 헤드로 나눈 뒤 병렬로 어텐션을 수행하고, 이를 결합해 출력하는 구조이다.
마치 여러 사람이 한 문장을 각기 다른 관점에서 분석하는 것과 비슷하다.
- 한 사람은 문법에 집중
- 다른 사람은 단어 간 의미적 연결에 주목
- 또 다른 사람은 문맥이나 뉘앙스를 살핌
class MultiHeadAttention(nn.Module):
def __init__(self, d_model, num_heads, dropout=0.1):
super(MultiHeadAttention, self).__init__()
assert d_model % num_heads == 0
self.d_k = d_model // num_heads
self.num_heads = num_heads
self.linear_q = nn.Linear(d_model, d_model)
self.linear_k = nn.Linear(d_model, d_model)
self.linear_v = nn.Linear(d_model, d_model)
self.linear_out = nn.Linear(d_model, d_model)
self.dropout = nn.Dropout(dropout)
def forward(self, query, key, value, mask=None):
batch_size = query.size(0)
# Linear projections + split into heads
def transform(x, linear):
x = linear(x) # (batch, seq, d_model)
x = x.view(batch_size, -1, self.num_heads, self.d_k)
return x.transpose(1, 2) # (batch, num_heads, seq, d_k)
q = transform(query, self.linear_q)
k = transform(key, self.linear_k)
v = transform(value, self.linear_v)
x, attn = scaled_dot_product_attention(q, k, v, mask=mask, dropout=self.dropout)
# concat heads
x = x.transpose(1, 2).contiguous().view(batch_size, -1, self.num_heads * self.d_k)
return self.linear_out(x)- 기본 텐서는 메모리에 행 우선(row-major) 순서로 저장됨.
- x.transpose(0, 1)은 행과 열의 순서를 바꿈.
- 메모리 상의 배치는 그대로 유지되지만, 텐서의 차원을 논리적으로만 바꾼 상태임
→ 즉, 메모리 레이아웃이 비연속적(Non-contiguous) 상태가 됨. - view() 함수는 메모리 상에서 연속적인 데이터 배치를 요구함.
→ 하지만 transpose()를 통해 생성된 텐서는 메모리 상의 데이터 배치가 비연속적이기 때문에 오류 발생!
Position-wise Feed Forward
Transformer 에서 각 위치의 출력에 독립적으로 적용되는 완전 연결 신경망.
모든 시퀀스 토큰에 동일한 가중치를 사용하며,
비선형 활성화 함수(ReLU)를 통해 변환한 뒤 다시 선형 변환을 수행하는 단계.
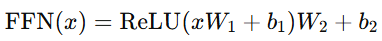
class PositionwiseFeedForward(nn.Module):
def __init__(self, d_model, d_ff, dropout=0.1):
super(PositionwiseFeedForward, self).__init__()
self.linear1 = nn.Linear(d_model, d_ff)
self.linear2 = nn.Linear(d_ff, d_model)
self.dropout = nn.Dropout(dropout)
def forward(self, x):
return self.linear2(self.dropout(F.relu(self.linear1(x))))Encoder
Encoder Layer는 Self-Attention과 Position-wise Feed Forward로 구성되며,
각 서브 레이어 후에 Residual Connection과 Layer Normalization가 적용됩니다.
class EncoderLayer(nn.Module):
def __init__(self, d_model, num_heads, d_ff, dropout=0.1):
super(EncoderLayer, self).__init__()
self.self_attn = MultiHeadAttention(d_model, num_heads, dropout)
self.feed_forward = PositionwiseFeedForward(d_model, d_ff, dropout)
self.norm1 = nn.LayerNorm(d_model)
self.norm2 = nn.LayerNorm(d_model)
self.dropout = nn.Dropout(dropout)
def forward(self, x, mask=None):
# Self-attention sublayer with residual connection and layer norm
attn_output = self.self_attn(x, x, x, mask)
x = self.norm1(x + self.dropout(attn_output))
# Feed-forward sublayer
ff_output = self.feed_forward(x)
x = self.norm2(x + self.dropout(ff_output))
return x
Encoder는 입력 시퀀스를 임베딩하고 포지셔널 인코딩을 추가한 뒤,
여러 개의 Encoder Layer 반복 수행해 고차원 표현으로 변환.
class Encoder(nn.Module):
def __init__(self, vocab_size, d_model, num_layers, num_heads, d_ff, dropout=0.1, max_len=100):
super(Encoder, self).__init__()
self.embedding = nn.Embedding(vocab_size, d_model)
self.pos_encoding = PositionalEncoding(d_model, max_len)
self.layers = nn.ModuleList(
[EncoderLayer(d_model, num_heads, d_ff, dropout) for _ in range(num_layers)]
)
self.dropout = nn.Dropout(dropout)
def forward(self, src, src_mask=None):
x = self.embedding(src) * math.sqrt(self.embedding.embedding_dim)
x = self.pos_encoding(x)
x = self.dropout(x)
for layer in self.layers:
x = layer(x, src_mask)
return xDecoder
Decoder Layer는 Masked Self-Attention, Encoder-Decoder Attention, Feed Forward 로 구성되며,
각 sub-layer 후에 Residual Connection과 Layer Normalization 가 적용
class DecoderLayer(nn.Module):
def __init__(self, d_model, num_heads, d_ff, dropout=0.1):
super(DecoderLayer, self).__init__()
self.self_attn = MultiHeadAttention(d_model, num_heads, dropout)
self.enc_dec_attn = MultiHeadAttention(d_model, num_heads, dropout)
self.feed_forward = PositionwiseFeedForward(d_model, d_ff, dropout)
self.norm1 = nn.LayerNorm(d_model)
self.norm2 = nn.LayerNorm(d_model)
self.norm3 = nn.LayerNorm(d_model)
self.dropout = nn.Dropout(dropout)
def forward(self, x, enc_output, src_mask=None, tgt_mask=None):
# Masked self-attention for decoder
self_attn_output = self.self_attn(x, x, x, tgt_mask)
x = self.norm1(x + self.dropout(self_attn_output))
# Encoder-decoder attention
enc_dec_attn_output = self.enc_dec_attn(x, enc_output, enc_output, src_mask)
x = self.norm2(x + self.dropout(enc_dec_attn_output))
# Feed-forward
ff_output = self.feed_forward(x)
x = self.norm3(x + self.dropout(ff_output))
return x
Decoder는 입력 시퀀스를 임베딩하고 포지셔널 인코딩을 추가한 뒤,
여러 개의 Decoder Layer 반복 수행해 출력을 생성.
class Decoder(nn.Module):
def __init__(self, vocab_size, d_model, num_layers, num_heads, d_ff, dropout=0.1, max_len=100):
super(Decoder, self).__init__()
self.embedding = nn.Embedding(vocab_size, d_model)
self.pos_encoding = PositionalEncoding(d_model, max_len)
self.layers = nn.ModuleList(
[DecoderLayer(d_model, num_heads, d_ff, dropout) for _ in range(num_layers)]
)
self.dropout = nn.Dropout(dropout)
def forward(self, tgt, enc_output, src_mask=None, tgt_mask=None):
x = self.embedding(tgt) * math.sqrt(self.embedding.embedding_dim)
x = self.pos_encoding(x)
x = self.dropout(x)
for layer in self.layers:
x = layer(x, enc_output, src_mask, tgt_mask)
return x디코더에서 마스크(mask)는 미래 정보의 참조를 막기 위해 사용됨.
- 패딩 마스크(Padding Mask) : 패딩 토큰이 어텐션에 영향을 주지 않도록 차단
- 룩 어헤드 마스크(Look-Ahead Mask) : 미래 시점의 토큰이 보이지 않도록 차단
현재 시점 이전의 값만 어텐션에서 참조하도록 설정
Transformer
위에서 만든 layer들을 연결하는 단계
class Transformer(nn.Module):
def __init__(self, src_vocab_size, tgt_vocab_size, d_model=256, num_layers=2,
num_heads=8, d_ff=512, dropout=0.1, max_len=100):
super(Transformer, self).__init__()
self.encoder = Encoder(src_vocab_size, d_model, num_layers, num_heads, d_ff, dropout, max_len)
self.decoder = Decoder(tgt_vocab_size, d_model, num_layers, num_heads, d_ff, dropout, max_len)
self.fc_out = nn.Linear(d_model, tgt_vocab_size)
def make_src_mask(self, src):
# src: (batch, src_len) -> mask: (batch, 1, 1, src_len)
mask = (src != vocab.word2idx[PAD_TOKEN]).unsqueeze(1).unsqueeze(2)
return mask
def make_tgt_mask(self, tgt):
# tgt: (batch, tgt_len)
batch_size, tgt_len = tgt.shape
# pad mask
pad_mask = (tgt != vocab.word2idx[PAD_TOKEN]).unsqueeze(1).unsqueeze(2) # (batch,1,1,tgt_len)
# subsequent mask (upper triangular)
subsequent_mask = torch.tril(torch.ones((tgt_len, tgt_len), device=tgt.device)).bool()
subsequent_mask = subsequent_mask.unsqueeze(0).unsqueeze(1) # (1,1,tgt_len,tgt_len)
mask = pad_mask & subsequent_mask
return mask
def forward(self, src, tgt):
src_mask = self.make_src_mask(src)
tgt_mask = self.make_tgt_mask(tgt)
enc_output = self.encoder(src, src_mask)
dec_output = self.decoder(tgt, enc_output, src_mask, tgt_mask)
output = self.fc_out(dec_output)
return output마스킹은 트랜스포머에서 패딩 토큰 제거와 미래 정보 차단을 위해 사용됨
- 소스 마스크(src_mask) → 입력에 패딩이 포함된 경우 패딩 토큰이 어텐션에서 무시되도록 설정
- 타겟 마스크(tgt_mask) → 미래 시점의 정보를 보지 못하도록 상삼각형 마스크 적용
Encoder output은 각 Decoder Layer에 다 들어감.
Train 준비
def train_epoch(model, dataloader, optimizer, criterion, clip=1.0):
model.train()
epoch_loss = 0
for src, tgt in dataloader:
src, tgt = src.to(device), tgt.to(device)
optimizer.zero_grad()
# decoder 입력은 tgt의 전체 sequence가 아니라 teacher forcing용으로 전체 tgt를 넣되, 예측은 오른쪽 shift되어 나온다.
# tgt 입력에서 마지막 토큰은 예측 대상이 아니므로, model에 넣을 때는 전체 시퀀스, loss 계산은 오른쪽 shift하여 진행
output = model(src, tgt[:, :-1])
# output: (batch, tgt_len-1, vocab_size)
output_dim = output.size(-1)
output = output.contiguous().view(-1, output_dim)
tgt_out = tgt[:, 1:].contiguous().view(-1)
loss = criterion(output, tgt_out)
loss.backward()
# gradient clipping
torch.nn.utils.clip_grad_norm_(model.parameters(), clip)
optimizer.step()
epoch_loss += loss.item()
return epoch_loss / len(dataloader)
output = model(src, tgt[:, :-1])
- Teacher Forcing → 이전 타임스텝의 정답을 디코더에 입력해 다음 타임스텝을 예측
- 마지막 토큰은 예측 대상이 아니므로 tgt[:, :-1]로 마지막 토큰 제외하고 디코더 입력
예제:
- tgt = [SOS, A, B, C, EOS]
- 디코더 입력 = [SOS, A, B, C]
- 출력 타겟 = [A, B, C, EOS]
이렇게 함으로써 디코더가 현재 시점의 입력에서 다음 토큰을 정확히 예측하도록 만듦.
tgt_out = tgt[:, 1:].contiguous().view(-1) → <sos>는 제외해도 되니
Gradient Clipping
torch.nn.utils.clip_grad_norm_(model.parameters(), clip)
그래디언트가 너무 커져 Gradient Explosion이 발생하는 것을 방지
clip = 1.0 → 그래디언트의 L2 노름이 1.0을 넘지 않게 클리핑
클리핑이 없으면 훈련이 불안정해지고 학습이 제대로 진행되지 않을 수 있음
def evaluate(model, dataloader, criterion):
model.eval()
epoch_loss = 0
with torch.no_grad():
for src, tgt in dataloader:
src, tgt = src.to(device), tgt.to(device)
output = model(src, tgt[:, :-1])
output_dim = output.size(-1)
output = output.contiguous().view(-1, output_dim)
tgt_out = tgt[:, 1:].contiguous().view(-1)
loss = criterion(output, tgt_out)
epoch_loss += loss.item()
return epoch_loss / len(dataloader)
Train & Validation
src_vocab_size = len(vocab)
tgt_vocab_size = len(vocab)
d_model = 256
num_layers = 2
num_heads = 8
d_ff = 512
dropout = 0.1
max_len = 40 # 토큰 최대 길이 (데이터에 맞게 조정)
model = Transformer(src_vocab_size, tgt_vocab_size, d_model, num_layers, num_heads, d_ff, dropout, max_len)
model = model.to(device)
optimizer = torch.optim.Adam(model.parameters(), lr=1e-4)
criterion = nn.CrossEntropyLoss(ignore_index=vocab.word2idx[PAD_TOKEN])
num_epochs = 10
best_val_loss = float('inf')
for epoch in range(num_epochs):
train_loss = train_epoch(model, train_loader, optimizer, criterion)
val_loss = evaluate(model, val_loader, criterion)
print(f"Epoch: {epoch+1:02}, Train Loss: {train_loss:.3f}, Val Loss: {val_loss:.3f}")
# 간단한 모델 저장 (val loss 기준)
if val_loss < best_val_loss:
best_val_loss = val_loss
torch.save(model.state_dict(), "best_transformer.pt")Inference
추론은 단순하게 Greedy Decoding으로 진행
- 디코더에서 다음 출력 토큰을 예측할 때, 가장 확률이 높은 토큰을 바로 선택
- 빔 서치(Beam Search) 같은 복잡한 탐색 없이 단순히 최대 우도(maximum likelihood) 값을 선택
def greedy_decode(model, src, max_len=30):
model.eval()
src = src.unsqueeze(0).to(device) # (1, src_len)
src_mask = model.make_src_mask(src)
enc_output = model.encoder(src, src_mask)
tgt_indices = [vocab.word2idx[SOS_TOKEN]]
for i in range(max_len):
tgt = torch.tensor(tgt_indices).unsqueeze(0).to(device) # (1, cur_len)
tgt_mask = model.make_tgt_mask(tgt)
dec_output = model.decoder(tgt, enc_output, src_mask, tgt_mask)
output = model.fc_out(dec_output) # (1, cur_len, vocab_size)
next_token = output[0, -1].argmax(dim=-1).item()
tgt_indices.append(next_token)
if next_token == vocab.word2idx[EOS_TOKEN]:
break
return [vocab.idx2word[idx] for idx in tgt_indices]
model.load_state_dict(torch.load("best_transformer.pt", map_location=device))
sample_idx = random.randint(0, len(test_dataset)-1)
sample_src, sample_tgt = test_dataset[sample_idx]
src_sentence = " ".join([vocab.idx2word[idx.item()] for idx in sample_src])
tgt_sentence = " ".join([vocab.idx2word[idx.item()] for idx in sample_tgt])
predicted = greedy_decode(model, sample_src, max_len=max_len)
predicted_sentence = " ".join(predicted)
print("질문: ", src_sentence)
print("정답: ", tgt_sentence)
print("예측: ", predicted_sentence)
굉장히 간단한 방식으로 구현했는데도
어느정도 문장의 구조를 잡아서 나름 연결성 있게 답변하는 것을 볼 수 있다.

이렇게 기본 모델을 잡고
적절한 훈련 단계 & 추론 단계 고도화 전략을 통해
모델을 튜닝하는 작업을 수행하면 된다.
1. 훈련 단계 고도화 전략
- 학습률 스케줄링 및 Warmup
- Label Smoothing
- Teacher Forcing Scheduling (Scheduled Sampling)
- Regularization 기법
- 데이터 증강 (Data Augmentation)
- Mixed Precision Training
- Gradient Accumulation
- Curriculum Learning
2. 추론 단계 고도화 전략
- Beam Search
- Sampling 기법
- Ensemble & Reranking
- Diverse Decoding



